
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- with recursive
- 프로그래머스
- 백준 16719
- 파이썬
- Kotlin
- JVM
- 백준 17626
- MSA
- 백준 17779
- 백준 19238
- 백준 16235
- springboot
- JPA
- MySQL
- 백준 파이썬
- sql 기술면접
- Spring Boot
- spring oauth
- 웹어플리케이션 서버
- spring security
- 백준
- java 기술면접
- java
- Spring
- 백준 16236
- re.split
- 프로래머스
- Coroutine
- spring cloud
- 백준 15685
- Today
- Total
시작이 반
[MSA] Spring Cloud ( Kafka 사용법 ) 본문
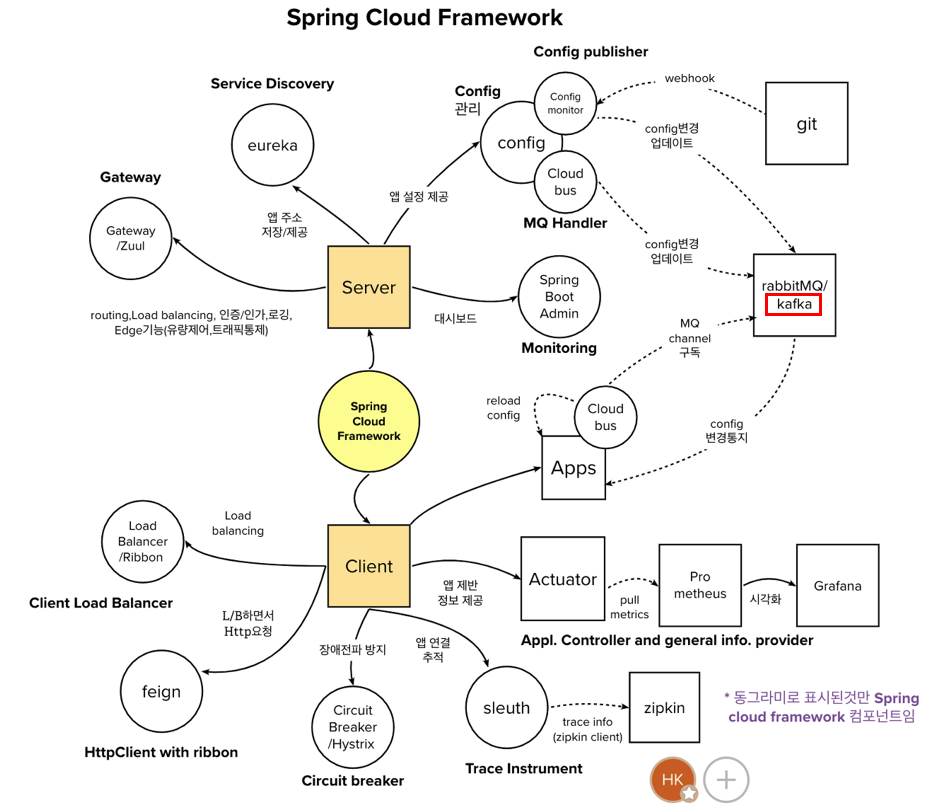
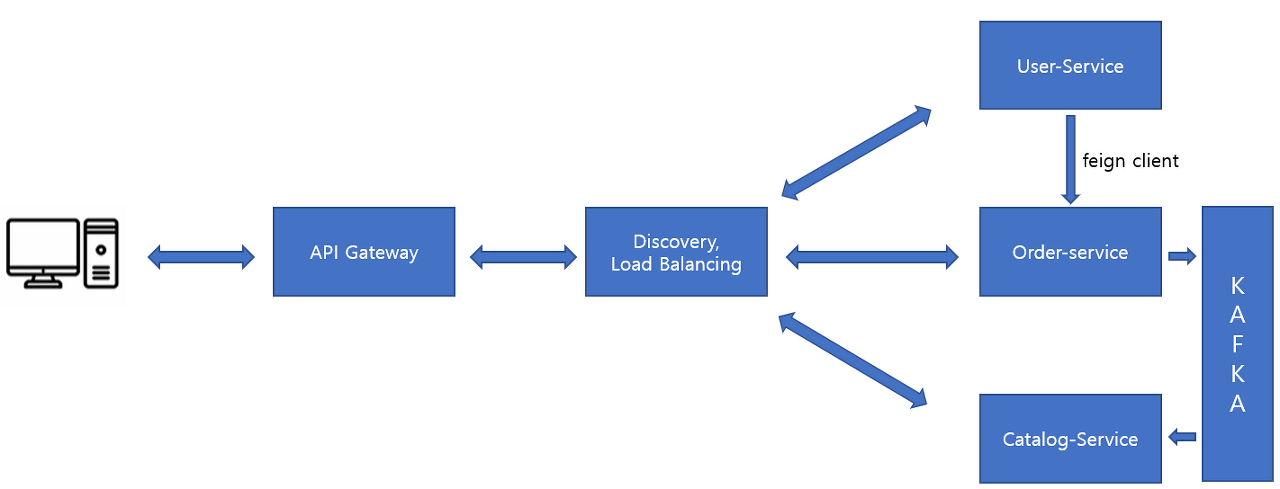
이전에는 FeignClient를 사용하여 user-service에서 http통신을 통해 order-service API를 불러왔다.
현재는 서비스마다 각각의 DB를 사용하고 있다.
하지만 order-service가 여러개 실행된다면 어떻게 될까??
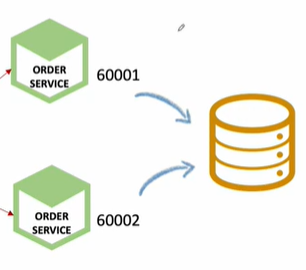
하나의 서비스가 여러개 실행된다면 각각 가지고 있는 DB또한 달라진다.
order-service1 ----- db1
order-service2 ----- db2
order-serivce3 ----- db3
....
그럼 이때 사용자가 주문을 하게된다면 어떻게 될까??
user1 사용자가 여러 주문을 하게된다면 처음에는 db1에 주문정보가 저장되고 다음 주문은 db2, 다음 주문은 db3, 또 다음 주문은 db1 이런식으로 round robin 형식으로 순차적으로 서비스가 돌아가면서 실행된다.
그러면 orders의 데이터정보가 분산저장되기때문에 user-service에서 user1의 주문목록을 가져오는 api를 실행하게된다면 처음 실행했을때는 db1에 있는정보 바로 다음에 실행하면 db2에 있는 정보.... 이렇게 분산된 정보를 가져온다.
원래는 user1이 주문한 모든주문 정보를 가져와야한다.
이러한 문제점을 해결하기 위한 방법
- 하나의 DB사용 ( 트랜잭션 문제를 잘해야함 )
- DB간의 동기화 ( Message Queuing Server를 이용 RabbitMQ, Kafka )
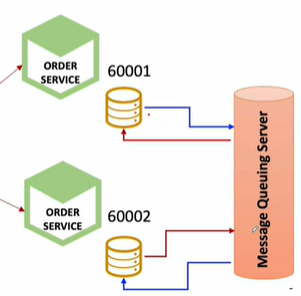
- Kafka Connector + DB

DB하나만 사용하는거랑 Kafka Connector + DB는 뭔 차이가있냐
Kafka Connect의 목적은 프로그래밍 작업을 최소화 하면서, Source의 데이터를 Target으로 옮기는데 있다.
DB이외에도 다양한 Source나 Target에 연결될 수 있다. 또한 Microservice에서 직접 DB에 대한 커넥션과 처리작업을 하지 않고 관련 작업은 Kafka에 일임 한다.
Kafka
자신들이 전송하는 데이터가 어떤 시스템에 사용되는지 상관하지 않고 Kafka에만 전달함으로써 단일 포멧만 사용한다.
보내는쪽과 받는쪽이 누가 보냈고 누가 받는지를 신경쓰지 않는다.
- Producer : 메시지를 보내는쪽 / Consumer : 메시지를 받는쪽
- 높은 처리량을 위한 메시지 최적화
- Scale-out 가능
- Eco-system
kafka Broker
- 실행된 Kafka 어플리케이션 서버
- 일반적으로 3대이상의 Broker를 Broker Cluster로 구성하는 것을 권장한다. 서버중 1대는 리더 역할을 한다.
- 한곳에 저장되었던 메시지들을 다른곳에 공유함으로써 하나의 Broker가 문제가 생겼을때 다른 Broker를 사용
- 서버의 상태, 서버의 문제 장애 체크, 복구 등을 위해 코디네이터 시스템을 연동해서 같이 사용하는데 Kafka에서는 Zookeper를 일반적으로 사용한다.
카프카 다운
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
카프카.zip 파일을 다운받고 C드라이브에 압출을 풀자 ( 다른곳에다 푸니까 폴더명이 길다고 실행이 안됐음 )

config 폴더를 보면 주키퍼와 카프카를 실해할때 실행되는 설정파일들이 있다.
카프카는 3개이상의 브로커를 클러스터해서 사용하는게 안정적이지만 일단 하나의 카프카, 하나의 주키퍼를 사용해서 카프카를 실행해보자
PowerShell를 실행하여 카프카를 다운받은 폴더로 가준다. (cd명렁어 사용)
window기준
주키퍼 , 카프카 구동
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
.\bin\windows\kafka-server-start.bat .\config\server.properties
(주키퍼서버 포트 : 2181, 카프카 서버 : 9092)
카프카는 메세지를 주고 받는 producer, consumer가 있는데 producer에서 메세지를 보내면 그 데이터는 Topic에 저장이 된다.
때문에 Topic을 생성하고 producer가 topic에 메세지를 보내고 consumer가 topic을 관심있다고 구독하면 consumer에 메세지가 전달된다.
Topic 생성
.\bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --create --topic 토픽이름 --partitions 1
Topic 목록 확인
.\bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --list

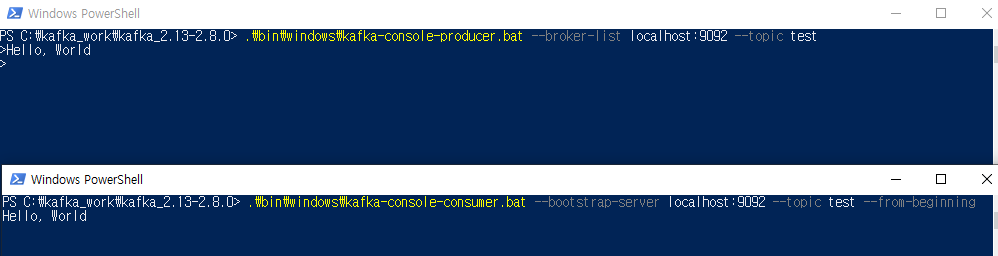
메시지 생산 (Producer)
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic 토픽이름
메시지 소비 (Consumer)
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic 토픽이름 --from-beginning
(from beginning : 처음부터 메시지를 받는 옵션)
Kafka Connect
- 데이터를 자유롭게 export/import
- 코드없이 configuration으로 데이터를 이용
- Standalone mode, Distribution mode 지원
- RESTful API 통해 지원
- Strea 또는 Batch 형태로 데이터 전송이 가능
- 커스텀 Connector를 통한 다양한 Plugin 제공 (File, S3, Hive, Mysql 등...)

여기서 source가 producer가 될 것이고 target이 consumer가 될 것이다.
Mraidb를 이용하여 실행해보자
Kafka connect 설치
- http://packages.confluent.io/archive/6.1/confluent-community-6.1.0.tar.gz
JDBC Connector 설치
- https://docs.confluent.io/5.5.1/connect/kafka-connect-jdbc/index.html
- confluentinc-kafka-connect-jdbc-10.0.1.zip
2개를 설치했다면
confluent 폴더의
etc/kafka/connect-distributed.properties 파일의 path부분에 jdbc폴더를 설치한 경로를 적어준다 ( lib경로 )

또한 JdbcSourceConnector에서 MariaDB를 사용하기 위해 mariadb드라이버를 복사해준다.
mariadb드라이버는 mariadb/jdbc/mariadb-java-clinet/버전 폴더에 있다.
confluent폴더/share/java/kafka/ 폴더에 mariadb-java-client-버전.jar 파일 복사
카프카 커넥터 실행
(주키퍼서버, 카프카서버가 우선 실행되어있어야함)
confluent폴더에 있는 connect를 실행한다.
.\bin\windows\connect-distributed.bat .\etc\kafka\connect-distributed.properties
커넥터를 실행하고 토픽을 확인해보면 3가지의 토픽이 새로 생긴 것을 볼 수 있다.

이제 카프카 source와 sink를 등록해야한다.
source는 데이터를 받아와서 topic에 옮겨주고 sinck는 topic데이터를 가져와서 target에 전달해준다.
카프카 connector 등록은 RESTful API를 통해 등록할 수 있다.
커넥터 포트번호 : 8083
source connet 생성
source connect는 외부의 source system과 연결해주는 역할을 하고 source system에서 전송된 값이 connect를 통해 topic에 저장된다.
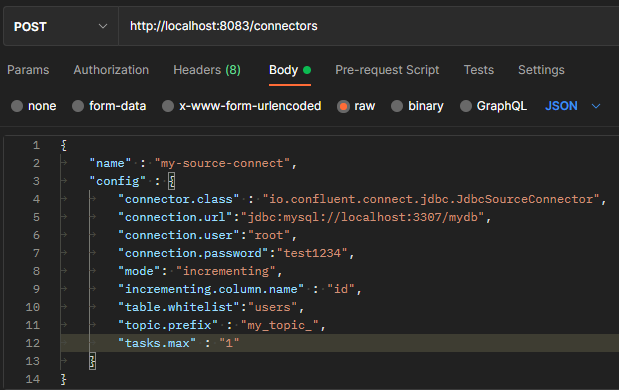
whitelist는 데이터베이스의 users table을 감지한다는 것
감지된 내용을 topic이름이 my_topic_users인 topic에 값을 전달한다.
이 이름은 topic.prefix와 table.whitelist값을 합친 값
커넥터 생성 확인

db랑 커넥터가 연결이 되었다.
db에 값을 insert해보자

연결된 db에 값을 넣고 topic을 확인하니 my_topic_users가 생긴 것을 볼수 있다.
이것은 위에서 생성한 커넥터의 설정값에서 topic.prefix와 table.whitelist값을 합친 값이다.

이번엔 이 topic에 들어있는 값을 확인하기 위해 consumer를 만들어서 확인해보자

db값을 insert해보니 이러한 정보가 들어갔다.
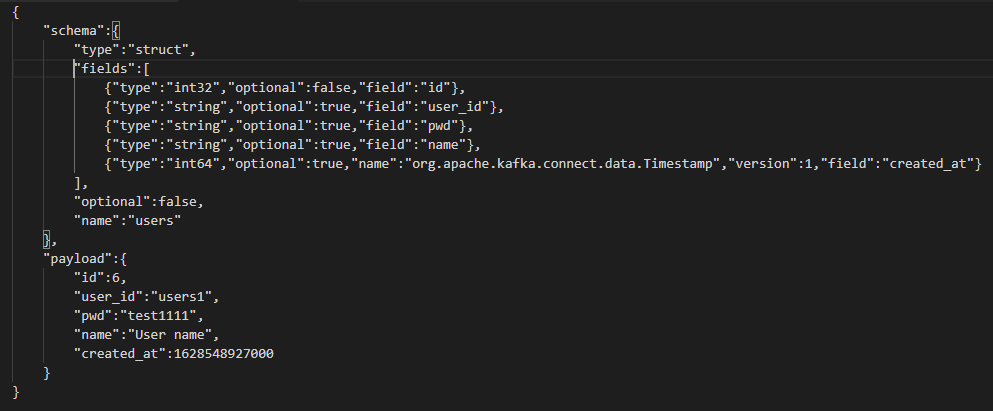
json형태의 값이 들어갔다.
schema와 payload가 key값으로 들어갔고 각각 value가 들어간 것을 확인할 수 있는데
schema : 데이터의 정보
payload : 데이터의 값
이번엔 sink connect를 만들어보자
sinck connect 생성
sinck connect는 topic에 저장된 값을 sink connect를 통해 가져오고 target system에 전송하는 역할을 한다.
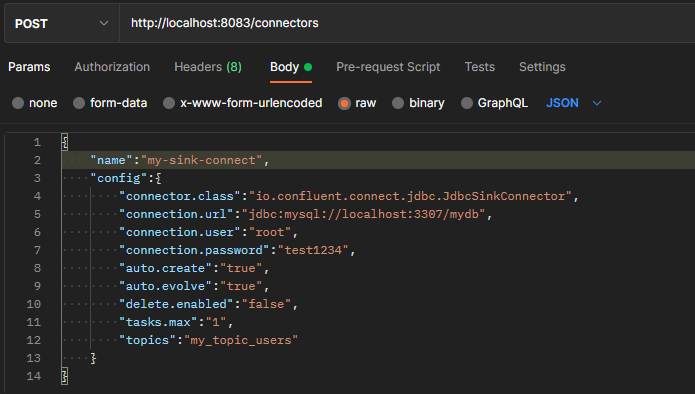
auto.create : topic과 같은 이름의 테이블을 자동으로 생성하겠다.
table의 구조는 topic에 저장되어있던 값을 가져와서 데이터로 해당 구조에 대해 table을 생성할 것이다.
커넥터 생성 확인
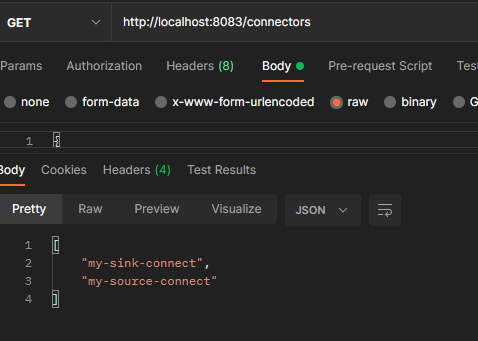
커넥터를 생성하면 topic의 정보로 table을 생성한다.
아래를 보면 my_topic_users의 table이 생성되어있으며 topic의 정보로 해당값이 insert된것을 볼 수 있다.
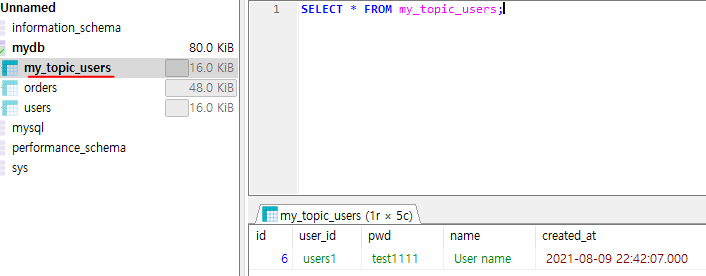
즉 topic 에 아래와같은 임의의 데이터가 아닌 유의미한 json형식인 데이터를 보내면 sink connect(jdbc인 sinck connector)가 이러한 형식을 해석해 target system(여기선 mariadb) 에 보내게된다.
'Programming > MSA' 카테고리의 다른 글
| [MSA] Spring Cloud ( Kafka connect - MariaDB 연결 ) (5) | 2021.08.16 |
|---|---|
| [MSA] Spring Cloud ( 데이터 동기화 Kafka 활용 ) (2) | 2021.08.11 |
| [MSA] Spring Cloud ( Microservice간 통신 - feignClient) (0) | 2021.08.08 |
| [MSA] Spring Cloud ( Config, Cloud bus ) (0) | 2021.08.07 |
| [MSA] Spring Cloud ( Config, actuator refresh ) (0) | 2021.08.07 |



